
Tenzing shows how a SQL engine built on top of MapReduce can enhance the power of standard SQL to provide deep analytic capabilities.
The paper mentioned above presents the architecture and implementation of “Tenzing” – which is an SQL query engine framework built on top of MapReduce. The authors also give benchmarks of typical analytical queries to allow comparison with existing relational database management systems. The paper states that the framework is currently being used at Google for ad hoc analysis of their data serving over 10,000 queries each day that span across two data centers, with two thousand cores each on 1.5 PB of compressed data. Tenzing was implemented as a replacement to a third-party data warehouse allowing for low or similar latencies, but adding the simplicity of SQL to it. It supports an almost complete SQL implementation along with several extensions. It has several key characteristics such as heterogeneity, high performance, scalability, reliability, metadata awareness, low latency, support for columnar storage and structured data, and easy extensibility.
“Tenzing” – which is an SQL query engine framework built on top of MapReduce. The authors also give benchmarks of typical analytical queries to allow comparison with existing relational database management systems. The paper states that the framework is currently being used at Google for ad hoc analysis of their data serving over 10,000 queries each day that span across two data centers, with two thousand cores each on 1.5 PB of compressed data.
The MapReduce framework is a widely popular framework for large scalable distributed data processing jobs. It is used inside Google as well as implemented by famous projects such as Apache Hadoop. But there exists a problem with this; for casual business users it is too complex as they need to learn distributed data processing and C++ or Java. Most of the simpler interfaces created as a solution suffer from high latency, low efficiency, and poor SQL support. But, the authors explain how Tenzing overcomes these limitations and provides a system with low latency, high throughput, high scalability, high resilience. It also provides with a comprehensive SQL92 implementation with some SQL99 extensions.
The authors have comprehensively defined the architecture of the system on how it utilizes the existing MapReduce framework by using a distributed worker pool. The pool, which consists of master and worker nodes along with an overall gatekeeper called the master watcher, accepts a query execution plan and executes Map Reduce jobs. Also the describe how tensing uses a metadata server to enhance queries and perform query optimizations. The authors have also stated the different client interfaces i.e. command line client (CLI), a Web UI and an API and how they can be used to utilize the different features of the framework.
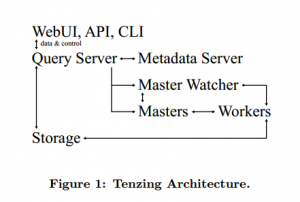
The paper describes in a simple manner the life cycle of a query viz. query submission, parsing, optimization, delegation of the execution plan by the master to the workers in the pool, gathering of the results and streaming to the client. This combined with the detailed architecture description helps build a picture on the workings of the framework. It is good to see that the paper acknowledges AsterData, GreenPlum, Paraccel, Vertica for using a MapReduce execution model in their engines.
All the SQL features supported by Tenzing have been explained with examples in the paper. In projection and filtering explanation they have pointed out the interesting features such as – for indexed sources along with a ranged query the compiler can just use the index for the particular
range. Also is states how the framework can work efficiently for ColumnIO data by prescanning the headers to determine if the file needs to be scanned. This could have been supported via examples to better explain the topic like the subsequent sections. Here, they emphasize on the extra features they were able to add on to the standard implementation e.g. support for Sawzall (procedural domain-specific programming language, used by Google) calls. For hash based aggregations the authors have given a detailed explanation of how Tenzing enhances the MapReduce framework to improve the performance of specific queries. The subsequent pseudo strengthens the explanation by giving a detailed logical flow of the feature.
The paper seems to give due importance to joins by proper describing all the join types and sub types supported by Tenzing. They also didn’t forget to mention the ones that the framework doesn’t support. This reflects self-criticism which is appreciable. The features section effectively reflects the efforts of the team to enhance and expand the features of the existing SQL implementations and also leveraging on the power of MapReduce.
In the last parts of the paper the authors have given the performance comparisons of Tenzing to various traditional MPP database systems such as Teradata, Netezza and Vertica. Through use of a master watcher, master pool and a worker pool they avoided spawning of new binaries for each new Tenzing query. Using this approach, we were able to bring down the latency to 10ms. This countable measure gives strength to their claims. They also gave specific examples of different techniques applicable to specific systems which could further improve performance e.g. Streaming & In-memory Chaining, Sort Avoidance, Block Shuffle etc. To show scalability they have provided the data comparing performance with 100, 500 and 1000 workers which show similar throughput in spite of having higher number of workers. This proves a significant improvement by Tenzing over traditional data warehousing systems. Finally, to further prove the effectiveness of Tenzing, the authors have provided us with various system benchmarks such as LLVM and Vector Engine. Most of the times Tenzing was faster than the traditional systems. But still it lacks in some scenarios, authors explain the reason being the LLVM Engine.
After reading the whole paper I could say that the paper was an extremely detailed one giving intricate details about the implementation of the framework. Still there were some areas which needed a bit more explanation. Firstly, it is given that to perform the query optimizations, Tenzing used information from a metadata server, but there is no information about the kind of metadata that is needed in. Though we can assume that it may refer to details about the data sources and data source metadata (indexes, access patterns, etc.) still a detailed explanation would make the description complete. Secondly, the authors described Tenzing as just a SQL implementation. They didn’t provide any details about the underlying storage and guarantees. Given that it runs on GFS and Bigtable, unless these technologies support the database ACID properties, we can say Tenzing won’t be able to support it either. Finally, the Tenzing framework is said to have been successfully replaced over the traditional warehousing system and provided the users with significantly more data, more powerful analysis capabilities, similar performance for most common scenarios, and far better scalability. The paper didn’t mention about the cost involved in this process which is important as it plays an important role in all enterprise level decisions.
The paper has a significant impact on standard data warehousing systems. The older systems had a lot of problems like lacking scalability, rapidly increasing load times and limitations of SQL and lack of access to multiple sources of data. The paper explains how Tenzing can solve these problems by providing an SQL interface to harness the power of MapReduce by providing a simpler wrapper interface over it which the non-engineering community (Sales, Finance, Marketing) could use for further productivity.
Conclusively, Tenzing shows how a SQL engine built on top of MapReduce can enhance the power of standard SQL to provide deep analytic capabilities. With relatively minor adjustments the authors were able to create a system which was comparable to commercial MPP DBMS in terms of throughput and latency and provided with added analytics capabilities. It also provided with highly scalability, high resilience simultaneously supporting heterogeneous data sources. Thus a smart system can be created on this framework which can fully utilize the characteristics of the underlying data sources resulting in better efficiency.
Paper Link: http://www.vldb.org/pvldb/vol4/p1318-chattopadhyay.pdf
Your post has moved the debate fodrwra. Thanks for sharing!